Nathan's Notes
Psycholinguistics and Transformer Circuits
Exploring the intricate web of word recognition in the brain, in relation to language models
Oct 15, 2025
Psycholinguistics studies how our minds process language - from recognizing sounds and words to understanding grammar and meaning. As we build increasingly sophisticated language models, it’s intriguing to consider how biological neural networks tackle the same fundamental challenges. What if we could peek inside both systems as they process language?
Before we dive in, try this yourself: Lexical Decision Task
You’ll see letter strings flash on screen - your job is to decide as quickly as possible whether each is a real word or not. Those tiny differences in response time reveal the underlying mechanics of word recognition.
What you just experienced demonstrates the core phenomena we’ll explore in this post. Individual trials vary, but repeat the task 100 times and clear patterns appear - systematic differences in response time that reveal how your brain processes language.
Facilitation and Inhibition in Word Recognition
The lexical decision task reveals two key phenomena that shape how we recognize words:
- Facilitation: Related words help each other. After seeing “doctor,” you recognize “nurse” faster.
- Inhibition: Similar words compete. In human word recognition, we see two types:
- Inhibitory Priming: Context-dependent. Seeing “stiff” makes you recognize “still” slower.
- Neighborhood Density: Context-independent. Words with more phonological neighbors are recognized slower.
Crucially, these effects depend on temporal correlation - the recency of when a word was heard or read directly influences the strength of facilitation or inhibition. Recent exposure creates stronger priming effects that decay over time, revealing how our word recognition system maintains a dynamic state influenced by recent linguistic experience.
These effects highlight how our brains balance quick recognition with the challenge of disambiguating similar-sounding words. This competition reveals that word recognition isn’t just about matching input to stored entries, but about navigating a complex network where activation spreads and competes.
The Associative Web
We don’t store words like a dictionary. There’s no alphabetical lookup in your brain. Instead, words exist in an associative web - a network where related concepts link together, and activating one word sends ripples through everything connected to it.
Notice that this idea isn’t unique to human cognition. In AI, word embeddings like Word2Vec create a similar associative structure. Words with related meanings cluster together in the embedding space, mirroring the semantic connections in our mental lexicon.
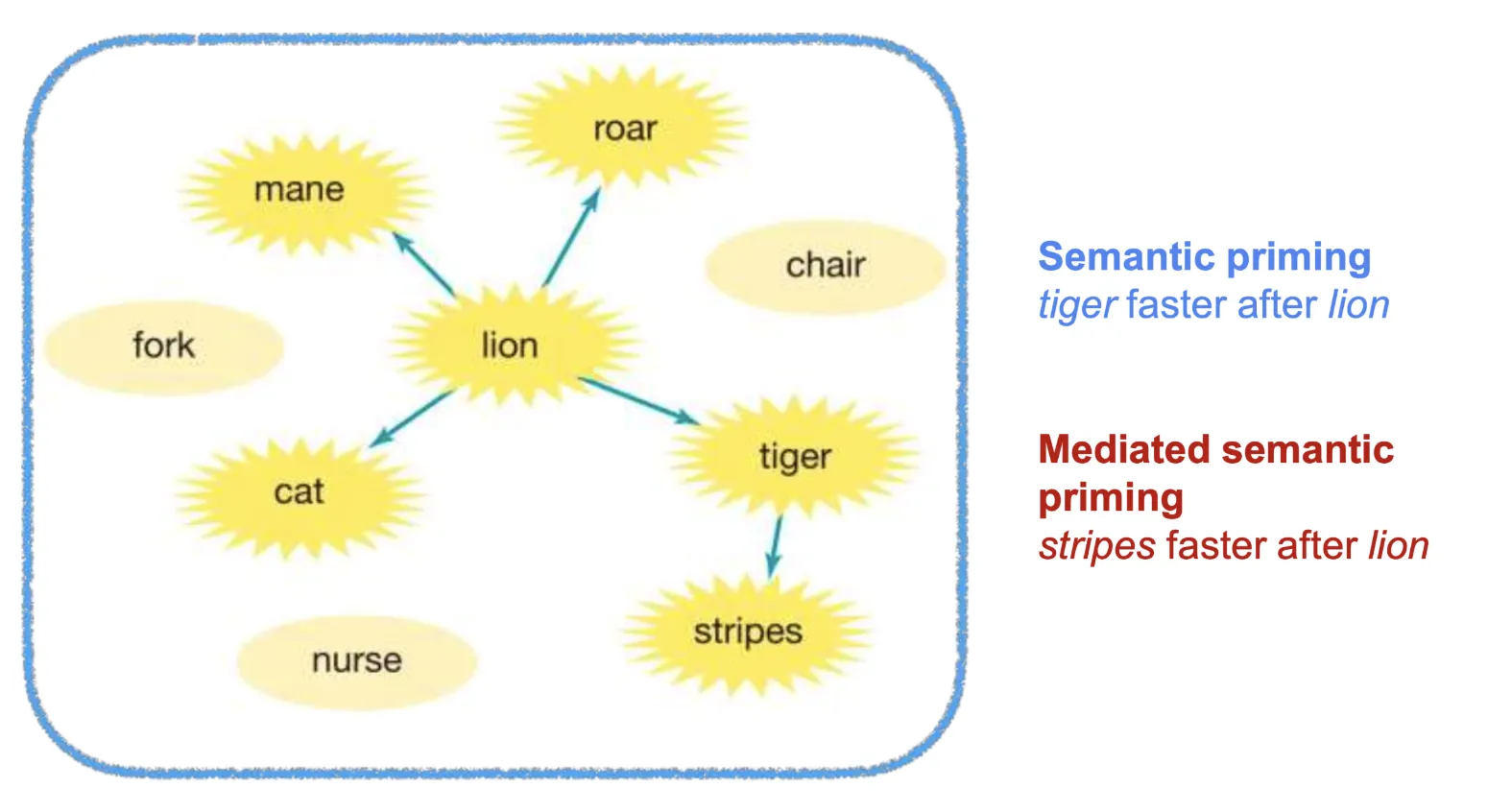
But in humans, looking at facilitation, why doesn’t everything get activated when we hear a word? Two key principles govern spreading activation:
- Spreading activation takes time - Neural signals don’t travel instantaneously
- Activation decays - Without sustained input, neural activity fades
The result: only local subnetworks get activated. This predicts that mediated priming should be weaker than direct priming. For instance, “tiger” should prime “stripes” less effectively than “lion” primes “tiger,” because the activation must travel through an intermediate node and decay along the way.
The Cohort Model and Parallel Activation
The Cohort Model, proposed by Marslen-Wilson (1987), suggests that as we hear a word, we activate a “cohort” of all possible words that match the input so far. For instance, hearing “gar-“ might activate garden, garbage, garlic, etc. As more phonemes are heard, the cohort narrows until only one word remains.
This parallel activation is remarkably efficient, allowing us to recognize words before they’re fully spoken. LLMs show a similar process when using phoneme-level (rather than “morpheme”-level) tokenization - they consider multiple possible continuations simultaneously as they generate sequences. The uncertainty from large cohort sizes mirrors high-entropy decision points in LLMs - moments of significant uncertainty about the next token. Both systems must resolve competition: brains between similar-sounding words in the cohort, LLMs between high-probability token candidates.
We can explicitly observe similar uncertainty patterns in human brains. The N400 component (~400ms) reflects semantic processing difficulty—larger responses indicate contextually unexpected or semantically unrelated words. The P300 component (~300ms) tracks categorization certainty, with diminished amplitude when stimulus properties conflict. In research involving antonym processing tasks, where participants judged whether semantically related words like “yellow” versus unrelated words like “nice” were antonyms of “black,” related non-antonyms showed reduced P300 amplitude, indicating lower decision certainty. This brain-based uncertainty signal parallels model entropy in LLMs, suggesting similar challenges in resolving semantic competition.
Phonological Complexity Beyond Cohorts
Interestingly, Allopenna et al. (1998) used eye-tracking to show that rhyme words (like “speaker” when hearing “beaker”) also attract associations, albeit less than cohort competitors. This challenges strict left-to-right processing models and suggests a more complex network of activation.
![]()
In their experiment, participants were asked to look at the center, then instructed to “look at the beaker.” The graph shows fixation probability over time for the target (beaker), cohort competitor (beetle), rhyme competitor (speaker), and unrelated distractor (carriage). Notice how both cohort and rhyme competitors initially attract attention before the target dominates.
The rhyme competitor effect is particularly intriguing. While the cohort model predicts that “beetle” should attract gaze when hearing “bee-“ (since it shares the initial phonemes), why would “speaker” compete when hearing “beaker”? They don’t share any initial sounds. This suggests something beyond simple left-to-right processing.
The TRACE model by McClelland & Elman (1986) offers an explanation. Rather than explicit rules, TRACE proposes that phonological knowledge rises from weighted connections between units - what appears to be rule-following is actually emergent behavior from simple interactions.
LLMs takes TRACE’s “emergent behavior” to its extreme, showing similar abilities to recognize rhymes and phonetic patterns despite being trained purely on text. Research on transformer circuits reveals how models develop emergent understanding of sound patterns through exposure to poems and explicit rhyme schemes, with no direct phonetic input.1
This mirrors the TRACE model’s insight: what appears to be explicit phonetic knowledge may actually be an artifact emerging from larger patterns in the data. Just as we inherit language from the society around us, LLMs inherit not only language but also implicit ideas about phonetics that they can’t directly experience. They develop understanding of rhymes, alliteration, and other sound patterns purely through statistical exposure to how humans use language. However, because LLMs are trained through tokenization schemes that prioritize meaning over phonetics, they’re unlikely to exhibit the same rich phonetic activation patterns that humans demonstrate.
As an example of rich phonological processing in humans: bilinguals automatically activate phonological representations from both languages when reading. In masked priming studies, where words flash too quickly for conscious processing, participants responded faster when prime and target words shared sounds across languages despite different meanings (like Dutch “wie” /wi/ and French “OUI” /wi/), demonstrating automatic cross-linguistic phonological activation. Interesting research could come out of deliberately exploring LLM’s phonetic associations in non-phonetic contexts (i.e. while not writing a poem).
Brains vs. LLMs: Fundamental Architectural Differences
While the parallels between human word recognition and AI language processing are striking, the underlying architectures reveal intricate differences that highlight the unique nature of biological cognition.
Memory and Time
The human brain operates as a fundamentally stateful system. Like state-space models such as Mamba or LSTMs, our neural networks maintain a self-contained “state” at each moment. However, the brain has additional complexity: activation spreads through networks with realistic time delays and decay functions. When you hear “lion,” activation doesn’t instantly appear everywhere but propagates gradually, weakening as it travels. This creates a natural temporal hierarchy where stronger, more direct connections win out over time as weaker signals fade.
Transformers work differently - they allocate expanding memory with each new token and lack built-in “decay.” Once information enters the context window, it remains equally accessible until pushed out entirely. LLMs achieve similar competitive effects through attention weights and learned representations, but without the continuous temporal evolution that characterizes biological processing.
Toward More Brain-Like Models
These architectural differences reveal both the remarkable capabilities of current AI systems and the unique computational principles evolution has discovered in biological brains. What would it take to build more brain-like language models? Three key features seem essential:
- Multimodality: Current models rely on text-derived inferences about sound, but humans have direct phonetic awareness - we explicitly recognize rhyme, meter, and phonological similarity. Models need intrinsic phonetic representations to properly capture inhibitory priming effects. The visual nature of many writing systems (like Mandarin characters) also remains largely unrepresented from tokenization schemes.2
- Self-Contained Memory: Unlike transformers that expand their context window with each token, brains maintain fixed-capacity states that compress and update information. This self-contained approach allows persistent memory without unbounded growth.
- Temporal Dynamics: Biological processing involves realistic time delays and decay - when you hear “lion,” activation propagates gradually through the network and weakens over time. This creates natural recency effects that determine priming strength. Transformers lack this temporal evolution, treating all context tokens as equally accessible.
The question isn’t whether we should replace transformers - their architectural differences make them excellent for different use cases than biological cognition. But could we build AI systems that truly mirror how brains process language? Such models might not only advance our understanding of human cognition but also unlock new approaches to language understanding that complement existing AI capabilities.
Multilingual transformer circuits research also interestingly reveals that language processing appears hierarchically separated, with three distinct computational parts: operation (e.g., antonym), operand (e.g., small), and language context. The hierarchical language separation reflects ideas from the Revised Hierarchical Model (RHM) for bilingual word recognition. RHM proposes that bilinguals maintain a hierarchy between their native language (L1) and second language (L2), where L2 words are initially accessed through L1 conceptual links before developing direct conceptual connections, reflecting debate on whether models think in English and Anthropic’s intervention experiments to change the output language. ↩
Rhyme recognition in LLMs can also theoretically be orthographically determined - “visually” learned from how words are written rather than how they sound. Depending on the granularity of tokenization schemes, models can identify that “cat,” “bat,” and “mat” share the same ending pattern. However, this orthographic approach can be misleading: words like “enough,” “trough,” and “cough” appear to rhyme orthographically but don’t actually share the same sounds, potentially leading to incorrect phonetic inferences in text-only trained models. ↩